1. 背景
如果栈空间开辟不足,程序运行过程中可能出现因栈溢出导致的各种莫名其妙的问题,尤其是有 RTOS 的情况下,这种情况下,相比于程序还能执行,但是结果不符合预期,发生 HardFault 反而可能是最好的结局,因为 HardFault 异常可以提供一个保存现场信息的契机,比如,可以在 HardFault 中断处理函数中查看或者保存 MSP、PSP、Fault 寄存器及各个任务的栈信息等。
本文以内核为 Cortex-M4 的 STM32 的某款单片机为例,着重介绍使用 Keil 开发带有 FreeRTOS 的应用时,如何根据任务栈的信息以及 Keil 生成的静态调用图文件进行栈溢出问题分析。
2. FreeRTOS 提供的栈溢出检测机制
FreeRTOS 提供了两种栈溢出检测方法,一种是在上下文切换时检测任务栈的最大深度,超出最大空间则调用回调函数;另一种是查看栈空间尾部的填充字节,如果填充字节被改写则调用回调函数。截至本文的写作时间,官网上显示的方法有三种,但是第三种貌似跟特定的架构有关,而且 FreeRTOS-Kernel 中也没有相关代码,本文先不讨论。
(1) 上下文切换时检测任务栈的最大深度
将 configCHECK_FOR_STACK_OVERFLOW 设置为 1 可启用该方法,在任务切换时,如果操作系统检测到任务栈的增长到达或者超出了任务栈的最大空间,就会调用回调函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void vTaskSwitchContext( void )
{
if( uxSchedulerSuspended != ( UBaseType_t ) pdFALSE )
{
/* The scheduler is currently suspended - do not allow a context
* switch. */
xYieldPending = pdTRUE;
}
else
{
/* 此处省略其他代码 */
/* Check for stack overflow, if configured. */
taskCHECK_FOR_STACK_OVERFLOW();
/* 此处省略其他代码 */
}
}
taskCHECK_FOR_STACK_OVERFLOW:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#if ( ( configCHECK_FOR_STACK_OVERFLOW == 1 ) && ( portSTACK_GROWTH < 0 ) )
/* Only the current stack state is to be checked. */
#define taskCHECK_FOR_STACK_OVERFLOW() \
{ \
/* Is the currently saved stack pointer within the stack limit? */ \
if( pxCurrentTCB->pxTopOfStack <= pxCurrentTCB->pxStack ) \
{ \
vApplicationStackOverflowHook( ( TaskHandle_t ) pxCurrentTCB, pxCurrentTCB->pcTaskName ); \
} \
}
#endif /* configCHECK_FOR_STACK_OVERFLOW == 1 */
#if ( ( configCHECK_FOR_STACK_OVERFLOW == 1 ) && ( portSTACK_GROWTH > 0 ) )
/* Only the current stack state is to be checked. */
#define taskCHECK_FOR_STACK_OVERFLOW() \
{ \
\
/* Is the currently saved stack pointer within the stack limit? */ \
if( pxCurrentTCB->pxTopOfStack >= pxCurrentTCB->pxEndOfStack ) \
{ \
vApplicationStackOverflowHook( ( TaskHandle_t ) pxCurrentTCB, pxCurrentTCB->pcTaskName ); \
} \
}
#endif /* configCHECK_FOR_STACK_OVERFLOW == 1 */
宏 portSTACK_GROWTH 表明栈的增长方向,Cortex-M4 的堆栈是向下增长的,即,从高地址往低地址增长,所以 portSTACK_GROWTH 为 -1,如果任务的栈顶指针小于等于任务栈空间的首地址则表明发生了栈溢出,发生栈溢出则会调用回调函数。
(2) 检测栈尾的填充字节是否被改写
将 configCHECK_FOR_STACK_OVERFLOW 设置为 2 可启用该方法,在任务切换时,如果操作系统检测到栈空间尾部的填充字节被改写则表明发生了栈溢出,就会调用回调函数。
FreeRTOS 在进行任务初始化时,如果相关宏开启,会使用特定值填充栈空间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static void prvInitialiseNewTask( TaskFunction_t pxTaskCode,
const char * const pcName, /*lint !e971 Unqualified char types are allowed for strings and single characters only. */
const uint32_t ulStackDepth,
void * const pvParameters,
UBaseType_t uxPriority,
TaskHandle_t * const pxCreatedTask,
TCB_t * pxNewTCB,
const MemoryRegion_t * const xRegions )
{
/* 此处省略其他代码 */
/* Avoid dependency on memset() if it is not required. */
#if ( tskSET_NEW_STACKS_TO_KNOWN_VALUE == 1 )
{
/* Fill the stack with a known value to assist debugging. */
( void ) memset( pxNewTCB->pxStack, ( int ) tskSTACK_FILL_BYTE, ( size_t ) ulStackDepth * sizeof( StackType_t ) );
}
#endif /* tskSET_NEW_STACKS_TO_KNOWN_VALUE */
/* 此处省略其他代码 */
}
填充字节 tskSTACK_FILL_BYTE 的值为 0xA5:
1
2
3
4
5
/*
* The value used to fill the stack of a task when the task is created. This
* is used purely for checking the high water mark for tasks.
*/
#define tskSTACK_FILL_BYTE ( 0xa5U )
宏 tskSET_NEW_STACKS_TO_KNOWN_VALUE 的值受一些可以由开发者设置的宏的值的影响:
1
2
3
4
5
6
7
8
/* If any of the following are set then task stacks are filled with a known
* value so the high water mark can be determined. If none of the following are
* set then don't fill the stack so there is no unnecessary dependency on memset. */
#if ( ( configCHECK_FOR_STACK_OVERFLOW > 1 ) || ( configUSE_TRACE_FACILITY == 1 ) || ( INCLUDE_uxTaskGetStackHighWaterMark == 1 ) || ( INCLUDE_uxTaskGetStackHighWaterMark2 == 1 ) )
#define tskSET_NEW_STACKS_TO_KNOWN_VALUE 1
#else
#define tskSET_NEW_STACKS_TO_KNOWN_VALUE 0
#endif
同样的,portSTACK_GROWTH 表明栈的增长方向,方向不同,栈尾空间所在的位置不同,如果栈向下增长,则栈空间的开始是栈尾,反之,栈空间的末尾是栈尾。如果栈尾的填充字节被改写,表明发生了栈溢出,就会调用回调函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#if ( ( configCHECK_FOR_STACK_OVERFLOW > 1 ) && ( portSTACK_GROWTH < 0 ) )
#define taskCHECK_FOR_STACK_OVERFLOW() \
{ \
const uint32_t * const pulStack = ( uint32_t * ) pxCurrentTCB->pxStack; \
const uint32_t ulCheckValue = ( uint32_t ) 0xa5a5a5a5; \
\
if( ( pulStack[ 0 ] != ulCheckValue ) || \
( pulStack[ 1 ] != ulCheckValue ) || \
( pulStack[ 2 ] != ulCheckValue ) || \
( pulStack[ 3 ] != ulCheckValue ) ) \
{ \
vApplicationStackOverflowHook( ( TaskHandle_t ) pxCurrentTCB, pxCurrentTCB->pcTaskName ); \
} \
}
#endif /* #if( configCHECK_FOR_STACK_OVERFLOW > 1 ) */
#if ( ( configCHECK_FOR_STACK_OVERFLOW > 1 ) && ( portSTACK_GROWTH > 0 ) )
#define taskCHECK_FOR_STACK_OVERFLOW() \
{ \
int8_t * pcEndOfStack = ( int8_t * ) pxCurrentTCB->pxEndOfStack; \
static const uint8_t ucExpectedStackBytes[] = { tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, \
tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, \
tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, \
tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, \
tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE, tskSTACK_FILL_BYTE }; \
\
\
pcEndOfStack -= sizeof( ucExpectedStackBytes ); \
\
/* Has the extremity of the task stack ever been written over? */ \
if( memcmp( ( void * ) pcEndOfStack, ( void * ) ucExpectedStackBytes, sizeof( ucExpectedStackBytes ) ) != 0 ) \
{ \
vApplicationStackOverflowHook( ( TaskHandle_t ) pxCurrentTCB, pxCurrentTCB->pcTaskName ); \
} \
}
#endif /* #if( configCHECK_FOR_STACK_OVERFLOW > 1 ) */
3. 栈空间开辟
由于本文中用到的是 Cortex-M4 的单片机,栈要分两个方面,一个是主栈,对应的栈帧寄存器是 MSP,另一个是任务栈,对应的栈帧寄存器是 PSP。
没有操作系统时(复位后,CPU 工作在 Thread 模式下,异常或中断时,CPU 工作在 Handle 模式下,默认都使用主栈),栈空间的开辟可能涉及到两个方面,一个是函数调用本身所需的栈空间,另一个是发生异常或中断时,CPU 自动压栈所需的栈空间。如果使用了操作系统(任务运行时,CPU 工作在 Thread 模式下,使用任务栈;异常或中断时,CPU 工作在 Handler 模式,使用主栈),还需要考虑任务切换时保存一些额外信息所需的栈空间。
上面提到的 Thread/Handler 模式切换,复位后,CPU 工作在 Thread 模式下,发生异常或中断时,CPU 工作在 Handle 模式下,从异常或中断返回前,可以通过 EXC_RETURN 的值来决定 CPU 退出异常或中断的行为,返回何种模式,有没有用 FPU 和使用哪个栈(涉及异常或中断完成后 CPU 自动从哪个栈出栈,以及后续执行流程中的入栈出栈)。
(1) 函数调用本身所需的栈空间
使用 Keil 时,借助 Keil 输出的静态调用图文件,可以很容易地获取这部分信息(后文中有如何生成该文件的说明)。下图是截取出来的一段信息,Max Depth 的值就是这个函数的调用链最深的时候所需的栈空间,即 116 字节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
min_send_frame (Thumb, 54 bytes, Stack size 32 bytes, min.o(i.min_send_frame))
[Stack]
Max Depth = 116
Call Chain = min_send_frame ⇒ on_wire_bytes ⇒ stuffed_tx_byte ⇒ crc32_step
[Calls]
>> min_tx_space
>> on_wire_bytes
[Called By]
>> vMessageHandler
>> transmit_data_realtime
>> vSendString
第一行还显示了 Stack size 是 32 字节,那 Max Depth 是否包含了这部分呢?这个也比较容易确定,看末级函数 crc32_step 的信息,Stack size 和 Max Depth 值相等,观察其他的末级函数,也是同样的情况,所以可以确定 Max Depth 包含了 Stack size。
1
2
3
4
5
6
7
8
9
10
11
12
crc32_step (Thumb, 40 bytes, Stack size 12 bytes, min.o(i.crc32_step))
[Stack]
Max Depth = 12
Call Chain = crc32_step
[Called By]
>> stuffed_tx_byte
>> rx_byte
(2) 发生异常或中断时,CPU 自动压栈所需的栈空间
这部分内容需要查看 CPU 内核的文档,例如《Cortex-M4 Devices Generic User Guide》中的“Exception entry and return”一节介绍了 Cortex-M4 分别在使用 FPU 和不使用 FPU 的情况下,发生异常或中断时,CPU 自动压栈的情况。还需要考虑可能存在的中断嵌套的问题。
(3) 操作系统进行任务切换时保存一些额外信息所需的栈空间
对于 FreeRTOS 来说,任务切换是在 xPortPendSVHandler 函数中完成的。该函数在进行任务切换时,会根据具体情况将 CPU 未自动入栈的寄存器以及可能涉及到的其他状态的寄存器压到任务栈中,因此,所需的栈空间要对该函数进行具体分析才能确定。
4. 调用链回溯
当有一些莫名其妙的问题发生时,往往需要根据栈的信息来进行调用链回溯,以尽可能找到引发这些问题的代码。如栈溢出、非对齐访问、数组越界等引发的 HardFault 问题,以及栈被其他任务踩了的这种飞来横祸的问题等。这一节解决两个问题,一是从任务栈中找出调用链,二是从 Keil 生成的静态调用图文件中解析出指定函数的所有调用链(用作参考)。
(1) 从任务栈中找出调用链
这部分内容可以参照 CmBacktrace 的代码。如果资源有限或不想使用 CmBacktrace 库,可以根据 cm_backtrace_call_stack_any 函数的具体实现,从任务栈中挑出所有符合函数地址的地址,结合 axf 文件及 map 文件进行调用链回溯。有飞来横祸的问题,可以从 map 文件中查看相邻地址段存放的是哪些数据,以帮助确定“元凶”。
(2) 从 Keil 生成的静态调用图文件中解析出指定函数的所有调用链
需要配置 Keil 工程,勾选 Project -> Options for Target -> Listing 中的 Callgraph:

勾选之后,重新编译,会生成一个 HTML 文件,该文件中有所有函数的调用信息及栈空间使用信息。
使用如下 Python 脚本可以从给定的静态调用图文件中解析出指定函数的所有调用链,并将其以 mermaid 流程图的形式输出到 markdown 文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
# -- coding: UTF-8 --
from bs4 import BeautifulSoup
import sys, copy
class TreeNode:
def __init__(self, func):
self.func = func
self.children = {}
def str(self, pad=0):
d = {}
if not self.children:
d = {
"func": self.func,
"children": "{}"
}
else:
# print("父函数: {}".format(self.func))
children_str_list = []
for c in self.children:
children_str_list.append(self.children[c].str())
# print("函数: {}, {}".format(self.children[c].func, self.children[c].str()))
children_str = ""
if len(children_str_list) == 1:
children_str += children_str_list[0]
else:
for i in range(0, len(children_str_list)):
if i == 0:
children_str += "{ %s" % children_str_list[i]
else:
children_str += ", {}".format(children_str_list[i])
if i == len(children_str_list) - 1:
children_str += "}"
# print("{}".format(children_str))
d = "{'func': %s, 'children': %s}" % (self.func, children_str)
return "{}".format(d)
def get_call_chain(func, funcs_dict):
node = TreeNode(func);
if funcs_dict[func]["Calls"]:
# 有下级函数,插入下级函数的节点
for calls in funcs_dict[func]["Calls"]:
child = get_call_chain(calls, funcs_dict)
node.children[calls] = child
return node
# 这个函数会打印出每条路径,会有重复的路径
def generate_call_chain_graph(call_chain, graph):
if not call_chain.children:
graph += "{}\n".format(call_chain.func)
# print(call_chain.func)
else:
for c in call_chain.children:
# print("{} --- ".format(call_chain.func), end='')
graph += "{} --- ".format(call_chain.func)
graph += generate_call_chain_graph(call_chain.children[c], "")
return graph
if __name__ == '__main__':
args = sys.argv[:]
if (len(args) != 3):
print("功能:使用 keil 生成的静态调用图文件,获取指定函数的调用链。")
print("使用方法:%s file.html 函数名" %(args[0]))
exit(1);
funcs_dict = {}
with open(args[1], 'r', encoding="utf8") as html_file:
soup = BeautifulSoup(html_file.read(), 'html.parser')
for strong in soup.find_all('strong'):
func_name = strong.get_text().strip()
# print("函数名:" + func_name)
func_dict = {"Calls": [], "Called By": []}
# 找父标签
p = strong.parent
# 找调用或被调用列表
for ul in p.find_all('ul'):
if ul.parent == p: # 通过限定父节点来确保只取第一级
# 获取标签前的文本,查找调用函数列表和被调用函数列表
if "[Calls]" in ul.previous_sibling.strip():
# print(" 发现调用函数列表:")
for li in ul.find_all("li"):
if li.parent == ul: # 通过限定父节点来确保只取第一级
# 将列表中的字符串提取出来,去掉两头的空白字符,放在列表中,然后从列表中删除 '>>',仅保留函数名称
func_dict['Calls'] = [func for func in list(li.stripped_strings) if func != ">>"]
# print(func_dict['Calls'])
elif "[Called By]" in ul.previous_sibling.strip():
# print(" 发现上级调用函数列表:")
for li in ul.find_all("li"):
if li.parent == ul: # 通过限定父节点来确保只取第一级
# 将列表中的字符串提取出来,去掉两头的空白字符,放在列表中,然后从列表中删除 '>>',仅保留函数名称
func_dict['Called By'] = [func for func in list(li.stripped_strings) if func != ">>"]
# print(func_dict['Called By'])
else:
pass
funcs_dict[func_name] = func_dict
# print("函数:")
# print(funcs_dict)
call_chain = get_call_chain(args[2], funcs_dict)
#print(call_chain.str())
# 生成调用链图
graph = generate_call_chain_graph(call_chain, "graph LR\n\n")
# 按行分割
graph_list = [str for str in graph.split('\n') if str != ""]
with open("graph_0.md", 'w', encoding="utf8") as md:
md.write("原始图:\n");
md.write("```mermaid\n");
md.write("%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%\n")
for l in graph_list:
md.write(l)
md.write("\n")
md.write("```")
# 去除重复的路径
res = []
[res.append(x) for x in graph_list if x not in res]
with open("graph_1.md", 'w', encoding="utf8") as md:
md.write("去除重复路径后的调用图:\n");
md.write("```mermaid\n");
md.write("%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%\n")
for l in res:
md.write(l)
md.write("\n")
md.write("```")
# 再次分割,只保留函数名
graph_list_of_list = [] # 二维列表
for l in res:
graph_list_of_list.append([str for str in l.split(' --- ') if str != ""])
#print("分割后的列表:")
#for l in graph_list_of_list:
# print(l)
# 精简路径,如果多条路径的最后的一段相同,则只保留一份
for i in range(0, len(graph_list_of_list)):
for j in range(i+1, len(graph_list_of_list)):
i_l = graph_list_of_list[i]
j_l = graph_list_of_list[j]
# 判断最后几个是否一样,如果一样,从 graph_list_of_list_reduce 中删除
same_func_num = 0; # 相同路径的长度
for k in range(0, min(len(i_l), len(j_l))):
if i_l[len(i_l) - k - 1] == j_l[len(j_l) - k - 1]:
continue
else:
same_func_num = k
break
# 删除 graph_list_of_list[j] 的最后 same_func_num-1 个元素
if same_func_num >= 2:
# print("删除最后 %d 个元素" % (same_func_num-1))
graph_list_of_list[j] = graph_list_of_list[j][:(-same_func_num+1)]
with open("graph_2.md", 'w', encoding="utf8") as md:
md.write("精简后的图:\n");
md.write("```mermaid\n");
md.write("%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%\n")
for l in graph_list_of_list:
md.write(" --- ".join(l))
md.write("\n")
md.write("```")
# 精简后的调用链图输出到控制台
for l in graph_list_of_list:
print(" --- ".join(l))
以如下的测试文件 test.html 为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
<!DOCTYPE html public "-//w3c//dtd html 4.0 transitional//en">
<html>
<head>
<title>
Static Call Graph - [.\Objects\test.axf]
</title>
</head>
<body>
<hr/>
<h1>
Static Call Graph for image .\Objects\test.axf
</h1>
<hr/>
<br/>
<p>
<strong>
<a name="[2ce]">
</a>
a
</strong>
(Thumb, 200 bytes, Stack size 10 bytes, app.o(i.a))
<BR><BR>[Stack]
<UL>
<LI>Max Depth = 86
<LI>Call Chain = a ⇒ b ⇒ d ⇒ f
</UL>
<BR>
[Calls]
<ul>
<li>
<a href="#[7d]">
>>
</a>
b
</li>
</ul>
<p>
<strong>
<a name="[7c]">
</a>
b
</strong>
(Thumb, 100 bytes, Stack size 16 bytes, app.o(i.b))
<BR><BR>[Stack]
<UL>
<LI>Max Depth = 76
<LI>Call Chain = b ⇒ d ⇒ f
</UL>
<BR>
[Calls]
<ul>
<li>
<a href="#[7d]">
>>
</a>
c
<li>
<a href="#[7d]">
>>
</a>
d
</li>
</li>
</ul>
<p>
<strong>
<a name="[2cf]">
</a>
c
</strong>
(Thumb, 80 bytes, Stack size 16 bytes, app.o(i.c))
<BR><BR>[Stack]
<UL>
<LI>Max Depth = 56
<LI>Call Chain = c ⇒ e
</UL>
<BR>
[Calls]
<ul>
<li>
<a href="#[7d]">
>>
</a>
e
</li>
</ul>
<p>
<strong>
<a name="[2d0]">
</a>
d
</strong>
(Thumb, 80 bytes, Stack size 20 bytes, app.o(i.d))
<BR><BR>[Stack]
<UL>
<LI>Max Depth = 60
<LI>Call Chain = d ⇒ f
</UL>
<BR>
[Calls]
<ul>
<li>
<a href="#[7d]">
>>
</a>
f
<li>
<a href="#[7d]">
>>
</a>
g
</li>
</li>
</ul>
<p>
<strong>
<a name="[2d0]">
</a>
e
</strong>
(Thumb, 0 bytes, Stack size 40 bytes, app.o(i.e))
<p>
<strong>
<a name="[2d0]">
</a>
f
</strong>
(Thumb, 0 bytes, Stack size 40 bytes, app.o(i.f))
<p>
<strong>
<a name="[2d0]">
</a>
g
</strong>
(Thumb, 0 bytes, Stack size 40 bytes, app.o(i.g))
</p>
</p>
</p>
</p>
</p>
</p>
</p>
</body>
</html>
获取函数 a 的调用链图:
1
python.exe call_graph_parser.py test.html a
有如下输出:
1
2
3
4
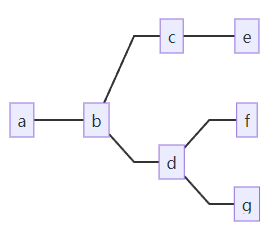
graph LR
a --- b --- c --- e
b --- d --- f
d --- g
使用支持 mermaid 的 markdown 文本编辑器打开生成的 markdown 文件,或者将输出的信息输入到 Mermaid Live Editor 中,就可以看到调用链关系图:
5. 总结
栈溢出问题需要从两个方面着手。
一方面是预防,在分配栈空间的时候就要考虑空间是否足够,如果没有操作系统,需要考虑两部分。一部分是函数本身的调用链所需的栈空间,可以从 Keil 生成的静态调用图文件中获取。另一部分是发生异常或中断时,CPU 自动压栈所需的栈空间(还需要考虑可能存在的中断嵌套的问题)。如果有操作系统,还得考虑任务切换时,保存一些额外信息所需的栈空间。
另一方面就是调用链回溯,从任务栈的内存空间中挑出函数地址,结合 axf 文件、map 文件以及静态调用图文件分析调用链。
6. 参考资料
[1] FreeRTOS stack usage and stack overflow checking